Data Structures
Data Structures Summary
By this point we've now examined four different ways to store sets of data:
There are even some variations on these (trees and heaps, quite similar to tries, stacks and queues quite similar to arrays or linked lists, etc.) but this will generally cover most of what we're looking at in C.
Arrays
-
Insertion is bad - lots of shifting to fit an element in the middle.
-
Deletion is bad - lots of shifting after removing an element.
-
Lookup is great - random access, constant time.
-
Relatively easy to sort.
-
Relatively small size-wise.
-
Stuck with a fixed size, no flexibility.
Linked lists
-
Insertion is easy - just tack onto the front.
-
Deletion is easy - once you find the element.
-
Lookup is bad - have to rely on linear search.
-
Relatively difficult to sort - unless you're willing to compromise on super-fast insertion and instead sort as you construct.
-
Relatively small size-wise (not as small as arrays).
Hash tables
-
Insertion is a two-step process - hash, then add.
-
Deletion is easy - once you find the element.
-
Lookup is on average better than with linked lists because you have the benefit of real-world constant factor.
-
Not an ideal data structure if sorting is the goal - just use an array.
-
Can run the gamut on size.
Tries
-
Insertion is complex - a lot of dynamic memory allocation, but gets easier as you go.
-
Deletion is easy - just free a node.
-
Lookup is fast - not quite as fast as an array, but almost.
-
Already sorted - sorts as you build in almost all situations.
-
Rapidly becomes huge, even with very little data present, not great if space is at a premium.
Pointers
In the memory notes, we learned about pointers, malloc, and other useful tools for working with memory.
Let's review the following snipped of code:
1 2 3 4 5 6 7 8 9 10 | |
Here, the first two lines of code in our main function are declaring two pointers, x and y. Then, we allocate enough memory for an int with malloc, and stores the address returned by malloc into x.
With *x = 42;, we got to the address pointed to by x, and stores the value of 42 into that location.
The final line, though, is buggy since we don't know what the value of y is, since we never set a value for it. Instead , we can write:
y = x;
*y = 13;
For a more fun way to understand the above, take a look at the short clip, Pointer Fun with Blinky.
Resizing arrays
In the arrays notes, we learned about arrays, where we could store the same kind of value in a list side-by-side. But we need to declare the size of arrays when we create them, and when we want to increase the size of the array, the memory surrounding it might be taken up by some other data.
One solution might be to allocate more memory in a larger area that's free, and move our array there, where it has more space. This sounds like it could work, but we'll need to copy our array, which becomes an operation with running time of O(n), since we need to copy each of n elements in an array.
We might write a program like the following, to do this in code:
copy array code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | |
It turns out that there’s actually a helpful function, realloc, which will reallocate some memory:
realloc example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
Data Structures
Data structures are programming constructs that allow us to store information in different layouts in our computer’s memory.
To build a data structure, we’ll need some tools we’ve seen:
-
structto create custom data types -
.to access properties in structure -
*to go to an address in memory pointed to by a pointer
Linked Lists
So far, we've only had one kind of data structure for representing collections of like values - struct - which give us "containers" for holding variables of different types, typically.
Arrays are great for element lookup, but unless we want to insert at the very end of an array, inserting elements is quite costly. Arrays also suffer from great inflexibility - what happens if we need a larger array than we thought?
Through clever use of pointers, dynamic memory allocation and structs, we can put the pieces together to develop a new kind of data structure that gives us the ability to grow and shrink a collection of like values to fit our needs.
We call this combination of elements, when used in this way, a linked list.
A linked list node is a special kind of struct with two members:
-
Data of some type (
int,char,float...) -
A pointer to another node of the same type
In this way, a set of nodes together can be thought of as forming a chain of elements that we can follow from beginning to end.
With a linked list, we can store a list of values that can easily be grown by storing values in different parts of memory:

- This is different than an array since our values are no longer next to one another in memory.
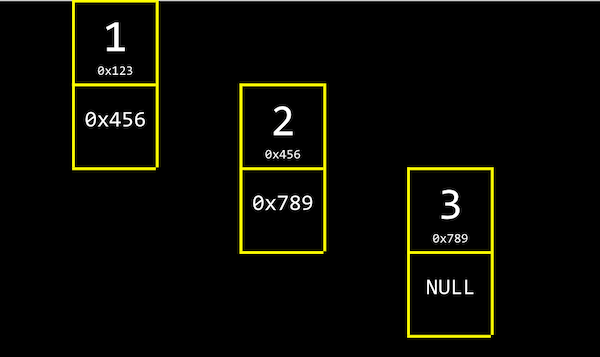
- This uses two chunks of memory, where the second chunk is used to point at the next chunk of memory. By the way,
NULrefers to\0, a character that ends a string, andNULLrefers to an address of all zeros, or a null pointer that we can think of as pointing nowhere. These chunks are linked by the pointers in the second chunk of memory.
In order to work with linked lists effectively, there are a number of operations that we need to understand:
Create a linked list
sllnode* create(VALUE val); // ssl stands for "single-linked list" in the following code
Steps involved:
-
Dynamically allocate space for a new
sllnode. -
Check to make sure we didn't run out of memory.
-
Initialize the node's
valfield. -
Initialize the node's
nextfield. -
Return a pointer to the newly created
sllnode.
Search through a linked list to find an element
bool find(sllnode* head, VALUE val);
Steps involved:
-
Create a traversal pointer pointing to the list's head.
-
If the current node's
valfield is what we're looking for, report success. -
If not, set the traversal point to the next pointer in the list and go back to step 2 (above).
-
If you've reached the end of the list, report failure.
Insert a new node into the linked list
sllnode* insert(sllnode* head, VALUE val);
Steps involved:
-
Dynamically allocate space for a new
sllnode. -
Check to make sure we didn't run out of memory.
-
Populate and insert the node at the beginning of the linked list.
-
Return a pointer to the new head of the linked list.
Delete a single element from a linked list
Deleting a single element from a singley-linked list can be a little tricky because it can cause different problems. There are solutions for this in doubley-linked lists.
Delete an entire linked list
void destroy(sllnode* head);
Steps involved:
-
If you've reached a null pointer, stop.
-
Delete the rest of the list.
-
Free the current node.
Additional linked list notes
Unlike with arrays, we no longer randomly access elements in a linked list. For example, we can no longer access the 5th element of the list by calculating where it is, in constant time. (Since we know arrays store elements back-to-back, we can add 1, or 4, or the size of our element, to calculate addresses.) Instead, we have to follow each element’s pointer, one at a time. And we need to allocate twice as much memory as we needed before for each element.
In code, we might create our own struct called node (like a node from a graph in mathematics), and we need to store both an int and a pointer to the next node called next.
1 2 3 4 5 6 | |
- We start this struct with
typedef struct nodeso that we can refer to anodeinside our struct.
We can build a linked list in code starting with our struct. First, we'll want to remember an empty list, so we can use the null pointer: node *list = NULL;.
To add an element, first we'll need to allocate some memory for a node, and set its values:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Now our list can point to this node: list = n;:
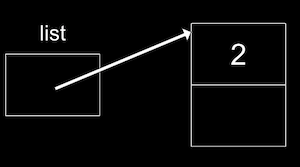
To add to our lsit, we'll create a new node the same way, perhaps with the value 4. But now we need to update the pointer in our first node to point to it.
since our list pointer points only to the first node (and we can't be sure that the list only has one node), we need to "follow the breadcrumbs" and follow each node's next pointer:
1 2 3 4 5 6 7 8 9 10 | |
If we want to insert a node to the front of our linked list, we would need to carefully update our node to point to the one following it, before updating the list. Otherwise, we'll lose the rest of our list:
1 2 3 4 5 | |
And to insert a node in the middle of our list, we can go through the list, following each element one at a time, comparing its values, and changing the next pointers carefully as well.
We can combine all of our snippets of code into a complete program:
node example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 | |
Hash Table
Hash tables combine the random access ability of an array with the dynamism of a linked list.
This means (assuming we define our hash table well):
-
Insetion can start to tend toward Θ(1)
-
Deletion can start to tend toward Θ(1)
-
Lookup can start to tend toward Θ(1)
Θ above stands for the average case.
We're gaining the advantages of both types of data structure (arrays & linked lists), while mitigating the disadvantages.
To get this performance upgrade, we create a new structure whereby when we insert data into the structure, the data itself gives us a clue about where we will find the data, should we need to look it up later.
A hash table amounts to a combination of two things:
-
First, a hash function, which returns a nonnegative integer value called a hash code.
-
Second, an array capable of storing data of the type we wish to place into the data structure.
The idea is that we run our data through the hash function, and then store the data in the element of the array represented by the returned hash code.
We can implement this in a hash table with an array of 26 pointers, each of which points to a linked list for a letter of the alphabet:
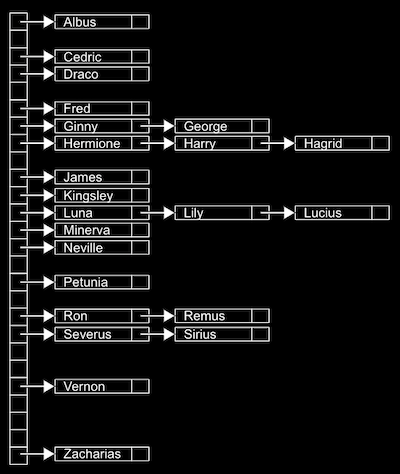
Since we have random access with arrays, we can add elements quickly, and also index quickly into a bucket.
A bucket might have might have multiple matching values, so we'll use a linked list to store all of them horizontally. (We call this a collision, when two values match in the same way.)
This is called a hash table because we use a hash function, which takes some input and maps it to a bucket it should go in. In our example, the hash function is just at the first letter of the name, so it might return 0 for "Albus" and 25 for "Zacharias".
But in the worst case, all the names might start with the same letter, so we might end up with the equivalent of a single linked list again. We might look at the first two letters, and allocate enough buckets for 26x26 possible hashed values, or even the first three letters, and now we’ll need 26x26x26 buckets. But we could still have a worst case where all our values start with the same three characters, so the running time for search is O(n). In practice, though, we can get closer to O(1) if we have about as many buckets as possible values, especially if we have an ideal hash function, where we can sort our inputs into unique buckets.
Tries
We can use another data structure called a trie (prounounced like "try", and is short for "retrieval"):
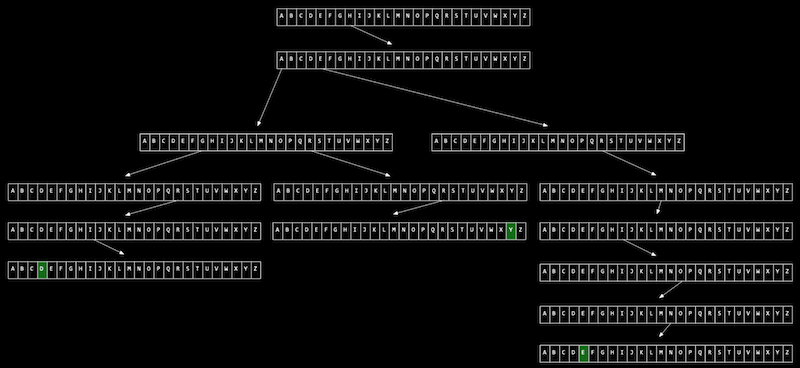
Tries combine structures and poiinters together to store data in an interesting way. The data to be searched for in the trie is now a roadmap. If you can follow the map from beginning to end, the data exists in the trie, if you can't, it does not exist in the trie. Unlike with a hash table, there are no collisions, and no two pieces of data (unless they are identical) have the same path.
Imagine we want to store a dictionary of words efficiently, and be able to access each one in constant time. A trie is like a tree, but each node is an array. Each array will have each letter, A-Z, stored. For each word, the first letter will point to an array, where the next valid letter will point to another array, and so on, until we reach something indicating the end of a valid word. If our word isn’t in the trie, then one of the arrays won’t have a pointer or terminating character for our word. Now, even if our data structure has lots of words, the lookup time will be just the length of the word we’re looking for, and this might be a fixed maximum so we have O(1) for searching and insertion. The cost for this, though, is 26 times as much memory as we need for each character.
More data structures
A tree is another data structure where each node points to two other nodes, one to the left (with a smaller value) and one to the right (with a larger value):
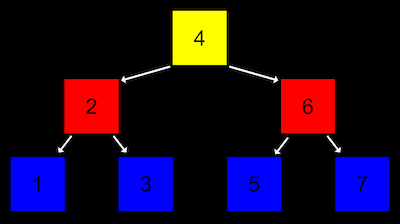
Notice that there are now two dimensions to this data structure, where some nodes are on different "levels" than others. We can imagine implementing this with a more complex version of a node in a linked list, where each node has not one but two pointers, one to the value in the "middle of the left half" and one to the value in the "middle of the right half". Note: all elements to the left of the node are smaller and all elements to the right are greater.
This is called a binary search tree because each node has at most two children, or nodes it is pointing to, and a search tree because it's sorted in a way that allows us to search correctly.
And like a linked list, we'll want to keep a pointer to just the beginning of the list, but in this case we want to point to the root, or top center node of the tree (the 4 in the image above).
Now, we can easily do binary search, and since each node is pointing to another, we can also insert nodes into the tree without moving all of them around as we would have to do with an array. Recursively searching this tree would look something like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
The running time of searching a tree is O(log n) and inserting nodes while keeping the tree balances is also O(log n). By spending a bit more memory and time to maintain the tree, we've now gained faster searching compared to a plain linked list.
There are even higher-level constructs, abstract data structures, where we use our building blocks of arrays, linked lists, hash tables, and tries to implement a solution to some problem.
For example, one abstract data structure is a queue, where we want to be able to add values and remove values in a first-in-first-out (FIFO) way. To add a value we might enqueue it, and to remove a value we would dequeue it. And we can implement this with an array that we resize as we add items, or a linked list where we append values to the end.
An “opposite” data structure would be a stack, where items most recently added (pushed) are removed (popped) first, in a last-in-first-out (LIFO) way. Our email inbox is a stack, where our most recent emails are at the top.
Another example is a dictionary, where we can map keys to values, or strings to values, and we can implement one with a hash table where a word comes with some other information (like its definition or meaning).